텍스트 데이터 벡터화 방법 및 작업자 위험 시나리오의 예제별 테스트
목표
오디오에서 추출된 텍스트 데이터를 벡터화하고, 유사한 과거 사례를 식별하거나 적절한 대응을 생성하기 위해 벡터 데이터베이스를 활용합니다. 이는 작업자 위험 상황(예: 낙상, 위험 장비 근처 접근, 유해 물질 노출)을 실시간으로 처리하고 분석하는 데 사용됩니다.
테스트 설정
- 데이터 소스:
- 음성 인식 시스템(예: Whisper, NVIDIA Riva)으로 처리된 오디오에서 추출된 텍스트 데이터.
- 텍스트는 작업자 위험을 설명하는 문장으로 구성됩니다.
- 벡터화 방법:
- SentenceTransformers (예: all-MiniLM-L6-v2).
- OpenAI의 CLIP 텍스트 인코더.
- DistilBERT 임베딩.
- 벡터 데이터베이스:
- FAISS를 사용하여 유사성 검색.
- 기존에 저장된 작업자 위험 사례 데이터로 데이터베이스를 구성.
- 평가 기준:
- 유사성 검색의 정확도 (코사인 유사도 기반).
- 데이터베이스 쿼리 속도.
- 유사 위험 상황 식별 정확도.
테스트 사례

다음은 시끄럽고 역동적인 작업 환경에서 실시간 위험 감지 및 대응 기능을 보여주는 Thingswell Inc에서 개발한 산업 안전 모니터링 시스템의 그림입니다. 이미지는 산업 환경에 통합된 데이터 처리 흐름과 안전 기능을 강조합니다.
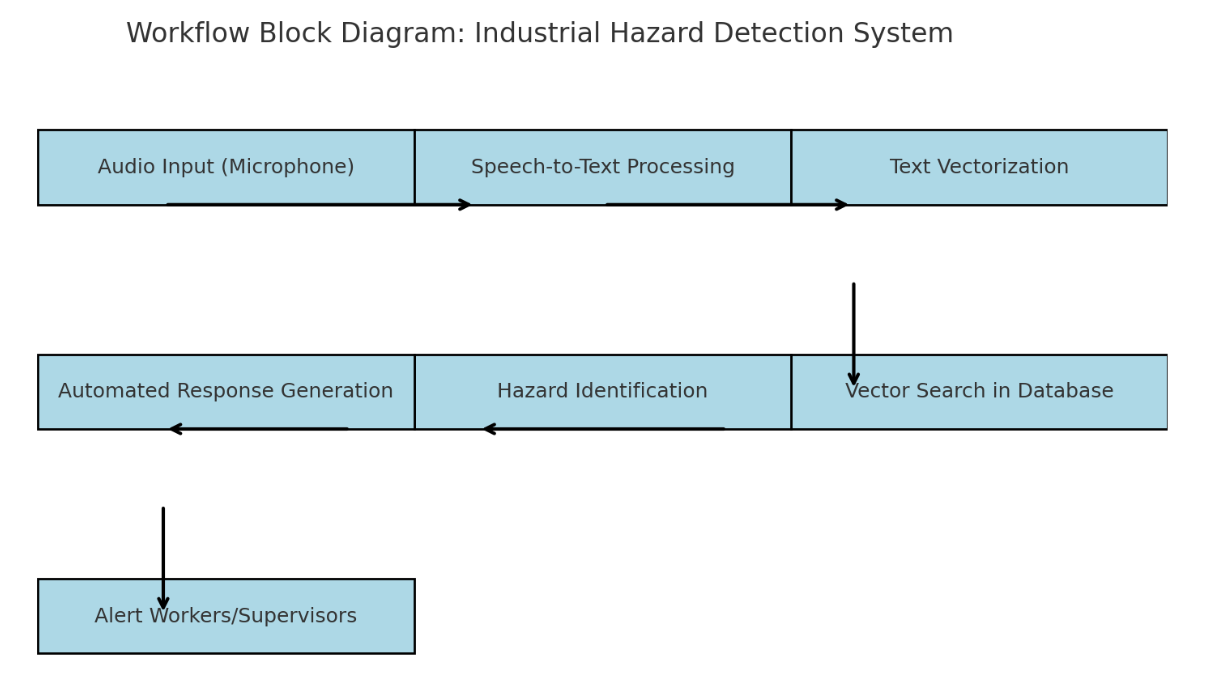
예제 1: 낙상 감지
- 상황:
- 오디오 처리: "도와주세요! 컨베이어 벨트 근처에서 미끄러졌어요."
- 추출된 텍스트: "작업자가 컨베이어 벨트 근처에서 낙상을 보고함."
- 벡터 생성:
- SentenceTransformers를 사용하여 텍스트를 벡터로 변환.
- 쿼리:
- 생성된 벡터를 데이터베이스에서 검색하여 유사 사례를 찾음.
- 예상 결과:
- 최상위 일치: "지난달 컨베이어 벨트 근처에서 작업자가 미끄러짐."
- 응답: "컨베이어 벨트 구역으로 응급 구조팀을 즉시 파견하십시오."
예제 2: 위험 장비 근처 접근
- 상황:
- 오디오 처리: "경고! 작업자가 유압 프레스 근처에 너무 가까이 있음."
- 추출된 텍스트: "작업자가 유압 프레스 근처에서 발견됨."
- 벡터 생성:
- DistilBERT를 사용하여 텍스트를 벡터화.
- 쿼리:
- 데이터베이스에서 위험 장비 근처 접근 사례 검색.
- 예상 결과:
- 최상위 일치: "지난주 유압 프레스 근처에서 작업자가 접근함."
- 응답: "작업자 및 감독자에게 안전 경고를 발송하십시오."
예제 3: 유해 물질 노출
- 상황:
- 오디오 처리: "라인 3 근처에서 화학물질 유출이 발생, 강한 냄새가 감지됨."
- 추출된 텍스트: "라인 3 근처에서 화학물질 유출 발생."
- 벡터 생성:
- OpenAI CLIP을 사용하여 텍스트를 벡터화.
- 쿼리:
- 화학물질 유출과 관련된 과거 사례 검색.
- 예상 결과:
- 최상위 일치: "2주 전 라인 3 근처에서 유해 화학물질 유출 발생."
- 응답: "해당 구역을 즉시 대피시키고 유해 물질 팀에 알리십시오."
예제 4: 작업자 건강 이상
- 상황:
- 오디오 처리: "도움이 필요합니다! 어지럽고 서 있을 수가 없어요."
- 추출된 텍스트: "작업자가 어지러움을 보고하고 서 있을 수 없다고 말함."
- 벡터 생성:
- SentenceTransformers를 사용하여 벡터화.
- 쿼리:
- 건강 이상과 관련된 사례를 데이터베이스에서 검색.
- 예상 결과:
- 최상위 일치: "지난달 작업자가 유해 가스 노출 후 어지러움을 호소함."
- 응답: "의료팀을 파견하고 가스 누출 가능성을 점검하십시오."
예제 5: 기계 오작동
- 상황:
- 오디오 처리: "기계 과열 중! 모터 하우징에서 연기가 발생."
- 추출된 텍스트: "모터에서 과열 및 연기 발생."
- 벡터 생성:
- DistilBERT를 사용하여 텍스트를 벡터화.
- 쿼리:
- 기계 오작동 사례 검색.
- 예상 결과:
- 최상위 일치: "지난해 유사한 기계에서 모터 과열 보고됨."
- 응답: "장비를 즉시 종료하고 유지보수 팀에 알리십시오."
평가 및 분석
1. 성능 평가
- 관련성:
- 검색된 사례와 현재 입력된 텍스트의 유사성이 높아야 함.
- 쿼리 속도:
- 벡터 검색 시간이 평균 50ms 이하인지 확인.
- 정확도 비교:
- SentenceTransformers, DistilBERT, CLIP의 결과를 비교하여 가장 높은 정확도를 확인.
2. 모델 및 데이터 최적화
- 임베딩 크기 감소:
- PCA를 사용하여 벡터 크기를 줄여 검색 속도 개선.
- 데이터베이스 업데이트:
- 새로운 사례 데이터를 지속적으로 추가하여 검색 정확도 향상.
최적화 전략
- 멀티모달 접근:
- 오디오, 텍스트, 비디오 데이터를 통합하여 상황을 더욱 정확히 파악.
- 실시간 처리:
- GPU 가속을 활용하여 임베딩 생성과 검색 속도 향상.
- 하이브리드 검색:
- 벡터 기반 검색과 키워드 기반 검색을 결합하여 정확도와 속도 최적화.
결론
이 테스트 시나리오는 텍스트 데이터 벡터화 및 데이터베이스 검색의 성능을 평가하고, 작업자 위험 상황을 효과적으로 처리하기 위한 기반을 제공합니다. 이 방법은 공장, 건설 현장 등 위험한 작업 환경에서 실시간으로 활용할 수 있습니다.
'기술자료' 카테고리의 다른 글
| 위험 상황 조기 감지 및 인터랙티브 알람 생성을 위한 모의 테스트 방법 및 리빙 랩 구축 방법 (0) | 2024.12.09 |
|---|---|
| 페르소나 모델 기법을 활용한 위험 상황 조기 감지 및 대화형 경보 생성을 위한 개발 방법개요 (0) | 2024.12.09 |
| 임베디드 마이크 시스템(USB)을 사용하여 Ubuntu에서 심층적인 소음 억제를 구현하는 개발 방법 및 예제 (1) | 2024.12.09 |
| 공장과 같은 시끄럽고 노이즈가 많은 환경에 적합한 오디오 처리 모델과 적용 방안 (2) | 2024.12.08 |
| rag llm 적용 방안 (4) | 2024.12.08 |

